
What is a Generalized AutoRegressive Conditional Heteroscedasticity (GARCH) process?
That’s a long fancy name for something that’s actually relatively simple. The overall context is time series analysis. Let’s sort out the terminology…
Scedasticity
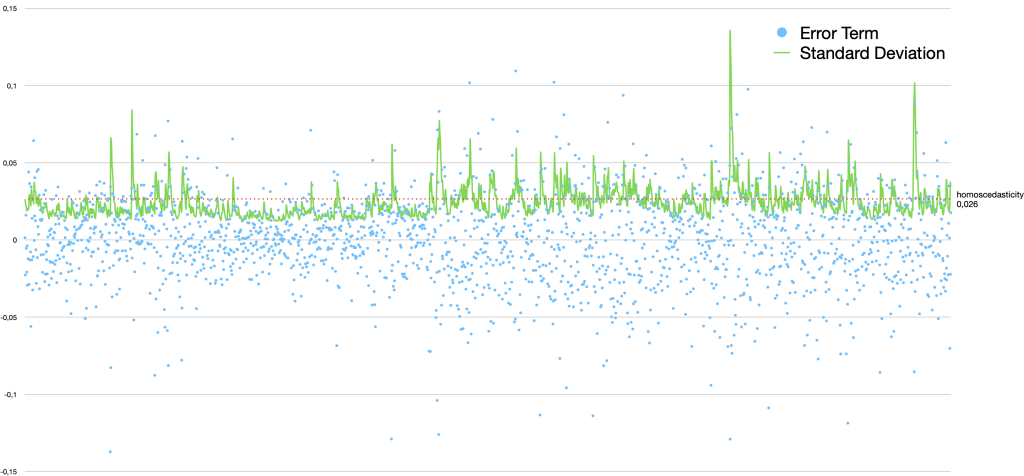
Scedasticity (or skedasticity) is the distribution of error terms (of some random variable). If the variance (and standard deviation) of the error term distribution is constant, we have homoscedasticity. If it’s varying with some kind of pattern we instead have heteroscedasticity. This is what GARCH models are used for – to model time series (financial markets) with turbulent periods of higher volatility than otherwise.
Conditional
In statistics conditional means that you already know something. Conditional probability is the probability of an event occurring, given that another event has already occurred. The concept of conditional probability is primarily related to Bayes’ theorem.
Stationary
Stationary simply means that it doesn’t move or change. A stationary process always has the same mean/expected value. A series of stock prices or index values is not stationary. To use a GARCH model it has to be transformed. Instead of studying the actual values, look at the increments and make those independent of (relative to) the current value (look at the log differences). That’s done with essentially any/all financial time series analysis. GARCH models are used on stationary processes. What changes is the magnitude of the temporary/local errors. It is because we have observed some previous values/errors (conditionality) we can calculate the current expected magnitude of the errors.
AutoRegressive
An autoregressive (regressive on itself) model is when a value from a time series can be expressed as a function of previous values.
AutoRegressive Conditional Heteroscedasticity
An AutoRegressive Conditional Heteroskedasticity (ARCH) model is a statistical model for the variance of a time series, that describe the variance of the current/next error term as a function of the actual (previous) error terms.
GARCH – Generalized AutoRegressive Conditional Heteroscedasticity
The ARCH model refers to a specific formula:

The term “AutoRegressive Conditional Heteroscedasticity” could refer to something much more general than that, but ARCH or ARCH(q) refers to that formula and nothing else. Generalized ARCH, GARCH or GARCH(p, q) also refers to a specific formula:

In fact it’s not that much of a generalisation. Instead of just a weighted sum of past squared errors, there is also a weighted sum of past variances. Since variance is estimated as the average squared error there is an obvious connection between the ARCH and GARCH formulas. In fact an ARCH(∞) model is equivalent to GARCH(1, 1).
Example Code
Console Output
class TimeSeriesGARCH
ojAlgo
2022-07-05
N225: First:1965-01-05=1965-01-05: 1257.719971 Last:2022-07-05=2022-07-05: 26423.470703 Size:14141
RUT: First:1987-09-10=1987-09-10: 168.970001 Last:2022-07-01=2022-07-01: 1727.76001 Size:8773
Coordinated daily : FirstKey=1987-09-10, LastKey=2022-07-01, NumberOfSeries=2, NumberOfSeriesEntries=9046
Coordinated weekly : FirstKey=1987-09-11, LastKey=2022-07-01, NumberOfSeries=2, NumberOfSeriesEntries=1817
Coordinated monthly : FirstKey=1987-09-30, LastKey=2022-07-31, NumberOfSeries=2, NumberOfSeriesEntries=419
Coordinated annually: FirstKey=1987-12-31, LastKey=2022-12-31, NumberOfSeries=2, NumberOfSeriesEntries=36
Correlations
1 0.506761
0.506761 1
Log difference statistics: Sample set Size=2997, Mean=0.0010084690273360743, Var=7.006664819240809E-4, StdDev=0.026470105438476835, Min=-0.27884405377306365, Max=0.15817096723925594
Error term statistics: Sample set Size=2997, Mean=1.2822020166779524E-17, Var=7.006664819240812E-4, StdDev=0.026470105438476842, Min=-0.27985252280039974, Max=0.15716249821191988
Variance
of log differences: 7.006664819240809E-4
of error terms : 7.006664819240812E-4
Volatility (annualized)
constant (homoscedasticity): 19.09%
of GARCH model (current/latest value): 21.94%
Pingback: ojAlgo v52 – oj! Algorithms
Hej!
Jag har en fråga! Om man vill hitta egenvektorerna för en symmetrisk matris. Vad är den absolut snabbaste algoritmen då?
Jag har börjat titta på One Side Jacobi SVD, där man utesluter E, och U matrisen och bara behåller V matrisen som innehåller eigenvektorerna. Då blir det gå riktigt skitsnabbt?
This could be suitable for GitHub Discussions: https://github.com/optimatika/ojAlgo/discussions
(and/or why not comment on a page about Eigenvalues? In English…)
I don’t know, start with a general algorithm that is fast and then modify it to avoid work on stuff you don’t want/need.
1) The ojAlgo SVD implementation is generally pretty fast (compared to other Java implementations)
2) It allows you to specify if you want the U and V matrices, to avoid work if in fact you don’t need them.
3) Even if you have specified that you want the U and V matrices, a significant portion of the work is not done until you actually ask to get those matrices, individually. If you don’t call getU(), the U matrix is not calculated.
4) The code could easily be refactored to allow individually wanting/needing the U and V matrices.
5) Making an SVD algorithm implementation correct, stable and fast is not a trivial task. I would try to make use of something that already exists.
If you want to continue this discussion, please move it to GitHub Discussions.